코틀린에서 단방향 데이터 흐름(UDF)와 뷰 모델의 활용

F-Lab : 상위 1% 개발자들의 멘토링
AI가 제공하는 얕고 넓은 지식을 위한 짤막한 글입니다!
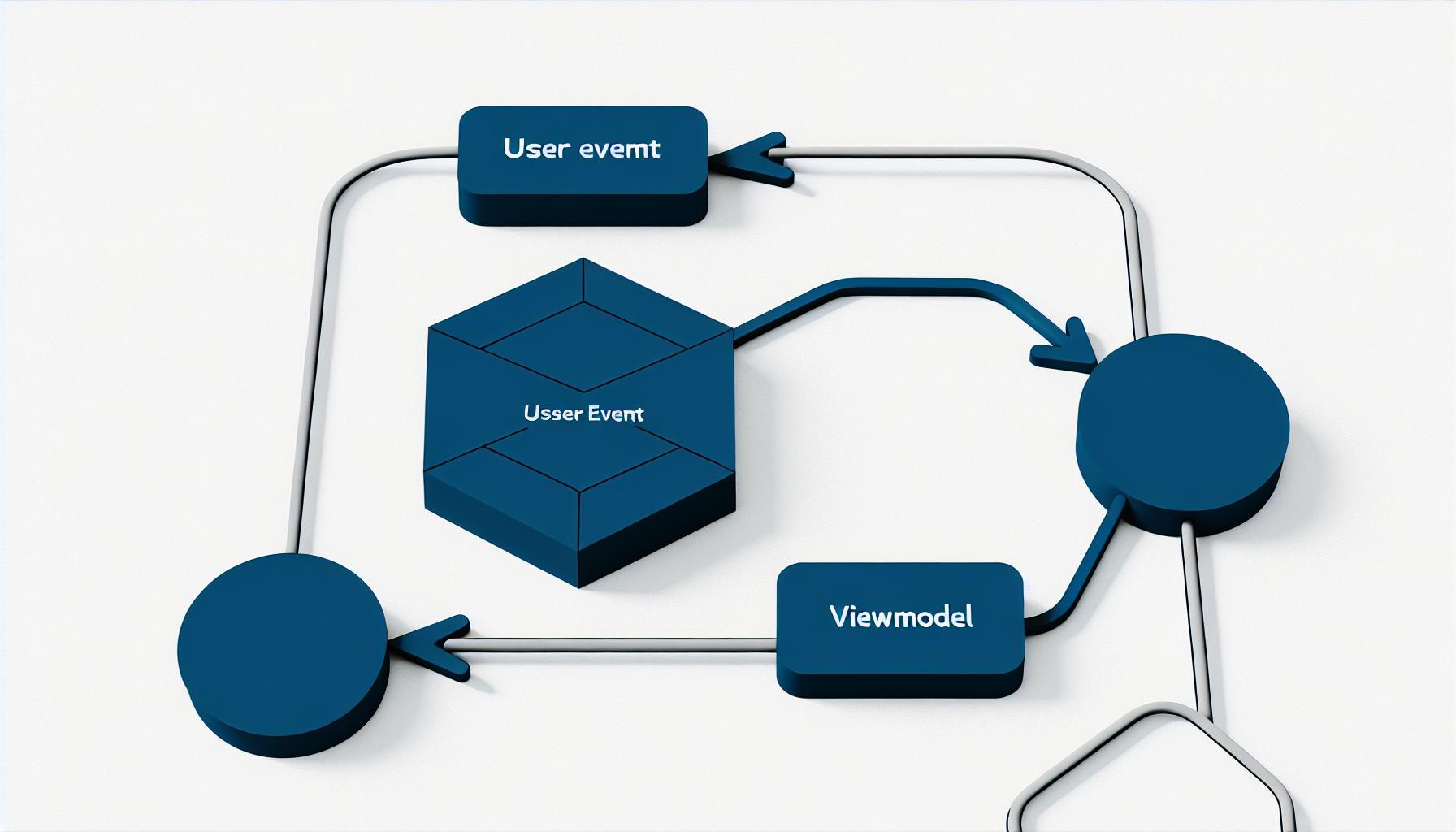
단방향 데이터 흐름(UDF)의 개념과 중요성
단방향 데이터 흐름(UDF, Unidirectional Data Flow)은 현대 애플리케이션 개발에서 중요한 패턴 중 하나입니다. 이 패턴은 데이터의 흐름을 한 방향으로 제한하여 상태 관리와 디버깅을 용이하게 만듭니다.
UDF는 사용자의 이벤트가 뷰 모델(ViewModel)로 전달되고, 뷰 모델이 상태를 업데이트한 후 UI에 반영되는 구조를 따릅니다. 왜냐하면 이러한 구조는 데이터의 흐름을 명확히 하고, 상태 관리의 복잡성을 줄여주기 때문입니다.
이 패턴은 특히 코틀린과 같은 언어에서 라이브 데이터(LiveData)와 함께 사용될 때 강력한 효과를 발휘합니다. 라이브 데이터는 옵저버 패턴을 기반으로 하여 데이터 변경 사항을 UI에 자동으로 반영할 수 있습니다.
UDF의 핵심은 상태(State)와 이벤트(Event)를 명확히 구분하는 것입니다. 상태는 UI를 렌더링하는 데 필요한 데이터이고, 이벤트는 사용자 상호작용을 나타냅니다.
이 글에서는 코틀린에서 UDF를 구현하는 방법과 뷰 모델을 활용하여 상태 관리를 최적화하는 방법을 살펴보겠습니다.
뷰 모델과 라이브 데이터의 역할
뷰 모델(ViewModel)은 안드로이드 아키텍처 컴포넌트 중 하나로, UI 관련 데이터를 관리하는 데 사용됩니다. 왜냐하면 뷰 모델은 프래그먼트나 액티비티의 라이프사이클에 독립적이기 때문입니다.
뷰 모델은 상태를 유지하고, 데이터 변경 사항을 라이브 데이터(LiveData)를 통해 UI에 전달합니다. 라이브 데이터는 옵저버 패턴을 기반으로 하여 데이터 변경 사항을 자동으로 감지하고 UI를 업데이트합니다.
예를 들어, 사용자가 버튼을 클릭하면 이벤트가 뷰 모델로 전달되고, 뷰 모델은 상태를 업데이트한 후 라이브 데이터를 통해 UI에 반영합니다. 이 과정은 단방향 데이터 흐름의 핵심입니다.
뷰 모델은 또한 테스트 가능성을 높이는 데 중요한 역할을 합니다. 왜냐하면 뷰 모델은 UI와 독립적으로 동작하기 때문에 유닛 테스트를 작성하기 용이하기 때문입니다.
다음 섹션에서는 뷰 모델과 라이브 데이터를 활용하여 단방향 데이터 흐름을 구현하는 방법을 코드 예제와 함께 살펴보겠습니다.
단방향 데이터 흐름 구현하기
단방향 데이터 흐름을 구현하려면 뷰 모델과 라이브 데이터를 효과적으로 활용해야 합니다. 아래는 코틀린에서 이를 구현하는 예제입니다.
class MyViewModel : ViewModel() {
private val _uiState = MutableLiveData()
val uiState: LiveData get() = _uiState
fun onButtonClick() {
_uiState.value = UiState.Loading
// 데이터 처리 로직
_uiState.value = UiState.Success("데이터 로드 완료")
}
}
class MyFragment : Fragment() {
private val viewModel: MyViewModel by viewModels()
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
viewModel.uiState.observe(viewLifecycleOwner) { state ->
when (state) {
is UiState.Loading -> showLoading()
is UiState.Success -> showData(state.data)
}
}
}
}
위 코드에서 뷰 모델은 상태를 관리하고, 프래그먼트는 상태를 관찰하여 UI를 업데이트합니다. 왜냐하면 상태와 이벤트를 명확히 구분하면 코드의 가독성과 유지보수성이 높아지기 때문입니다.
이러한 구조는 데이터의 흐름을 명확히 하고, 상태 관리의 복잡성을 줄여줍니다. 또한, 테스트 가능성을 높이는 데도 기여합니다.
다음 섹션에서는 단방향 데이터 흐름의 장점과 단점을 살펴보겠습니다.
단방향 데이터 흐름의 장점과 단점
단방향 데이터 흐름은 여러 가지 장점을 제공합니다. 첫째, 데이터의 흐름이 명확하여 디버깅이 용이합니다. 왜냐하면 데이터가 한 방향으로만 흐르기 때문에 문제의 원인을 쉽게 추적할 수 있기 때문입니다.
둘째, 상태 관리가 간단해집니다. 상태와 이벤트를 명확히 구분하면 코드의 가독성과 유지보수성이 높아집니다.
셋째, 테스트 가능성이 높아집니다. 뷰 모델은 UI와 독립적으로 동작하기 때문에 유닛 테스트를 작성하기 용이합니다.
그러나 단방향 데이터 흐름에도 단점이 있습니다. 첫째, 초기 구현이 복잡할 수 있습니다. 왜냐하면 상태와 이벤트를 명확히 정의하고, 이를 관리하는 로직을 작성해야 하기 때문입니다.
둘째, 코드가 길어질 수 있습니다. 상태와 이벤트를 명확히 구분하면 코드의 양이 늘어날 수 있습니다. 그러나 이러한 단점은 장점에 비해 상대적으로 작은 문제입니다.
결론: 단방향 데이터 흐름의 활용
단방향 데이터 흐름(UDF)은 현대 애플리케이션 개발에서 중요한 패턴입니다. 이 패턴은 데이터의 흐름을 명확히 하고, 상태 관리와 디버깅을 용이하게 만듭니다.
코틀린에서 뷰 모델과 라이브 데이터를 활용하면 UDF를 효과적으로 구현할 수 있습니다. 왜냐하면 뷰 모델은 상태를 관리하고, 라이브 데이터는 데이터 변경 사항을 UI에 자동으로 반영하기 때문입니다.
UDF는 상태와 이벤트를 명확히 구분하여 코드의 가독성과 유지보수성을 높입니다. 또한, 테스트 가능성을 높이는 데도 기여합니다.
이 글에서 소개한 내용을 바탕으로 UDF를 구현하고, 뷰 모델과 라이브 데이터를 활용하여 상태 관리를 최적화해 보세요. 이를 통해 더 나은 애플리케이션을 개발할 수 있을 것입니다.
다음 글에서는 UDF와 관련된 고급 주제와 실제 프로젝트에서의 활용 사례를 다룰 예정입니다.
이 컨텐츠는 F-Lab의 고유 자산으로 상업적인 목적의 복사 및 배포를 금합니다.
